Figure 6 detailed discussions
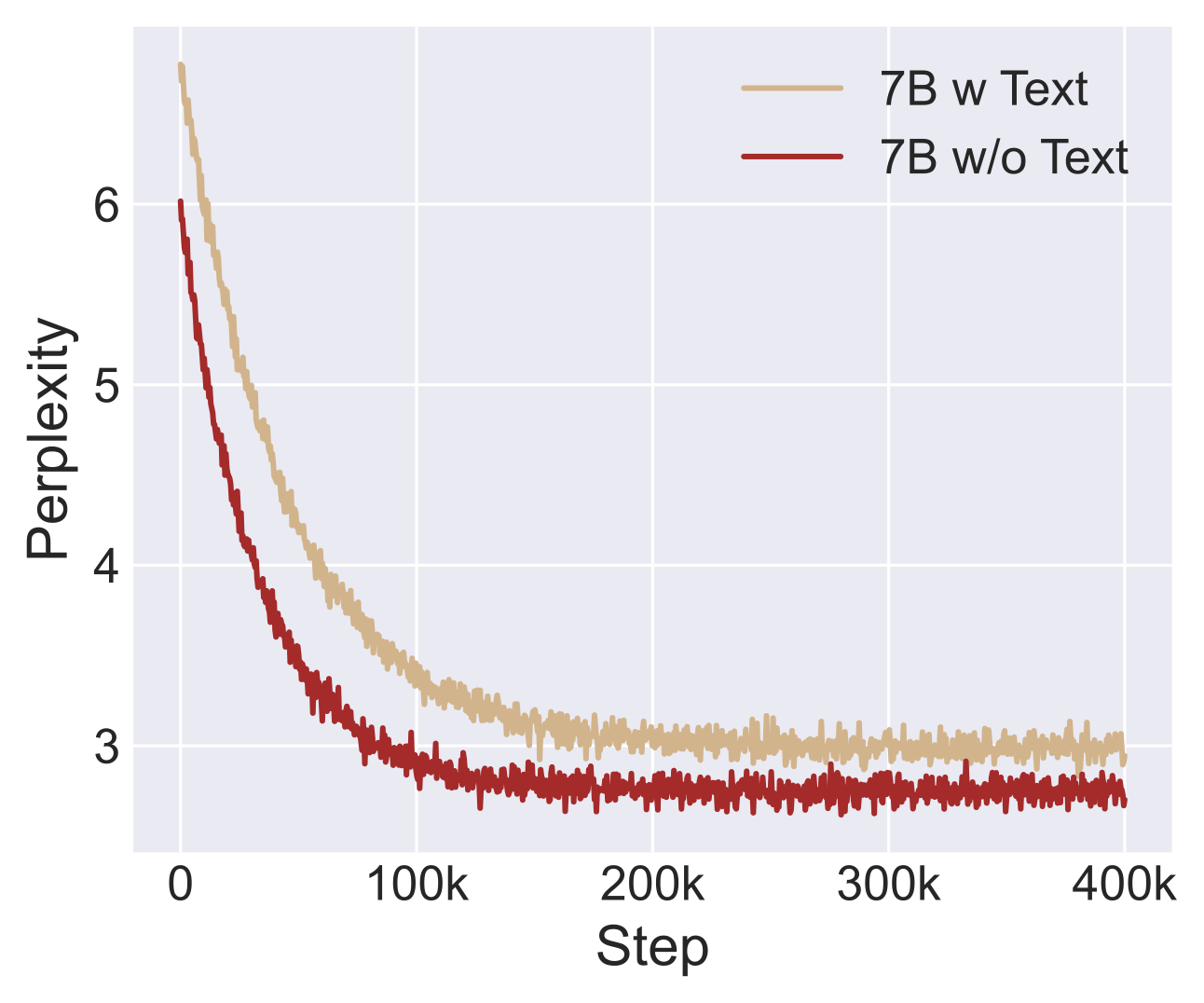
Figure 6: Comparison of training convergence between audio-only and text-included continue pre-training
Our architecture's full weight-sharing mechanism across modalities induces inter-modal gradient competition, where each modality subconsciously amplifies its parameter norms to gain dominance in the joint representation space. We conducted two continue pre-training experiments: When continuing pre-training with only audio interaction objectives (w/o ASR-driven text supervision), the model achieves faster convergence in perplexity reduction compared to "w Text training". This suggests that decoupling text modality during continue pretraining phases may mitigate cross-modal interference while maintaining dialog competency.
Figure 9 detailed discussions
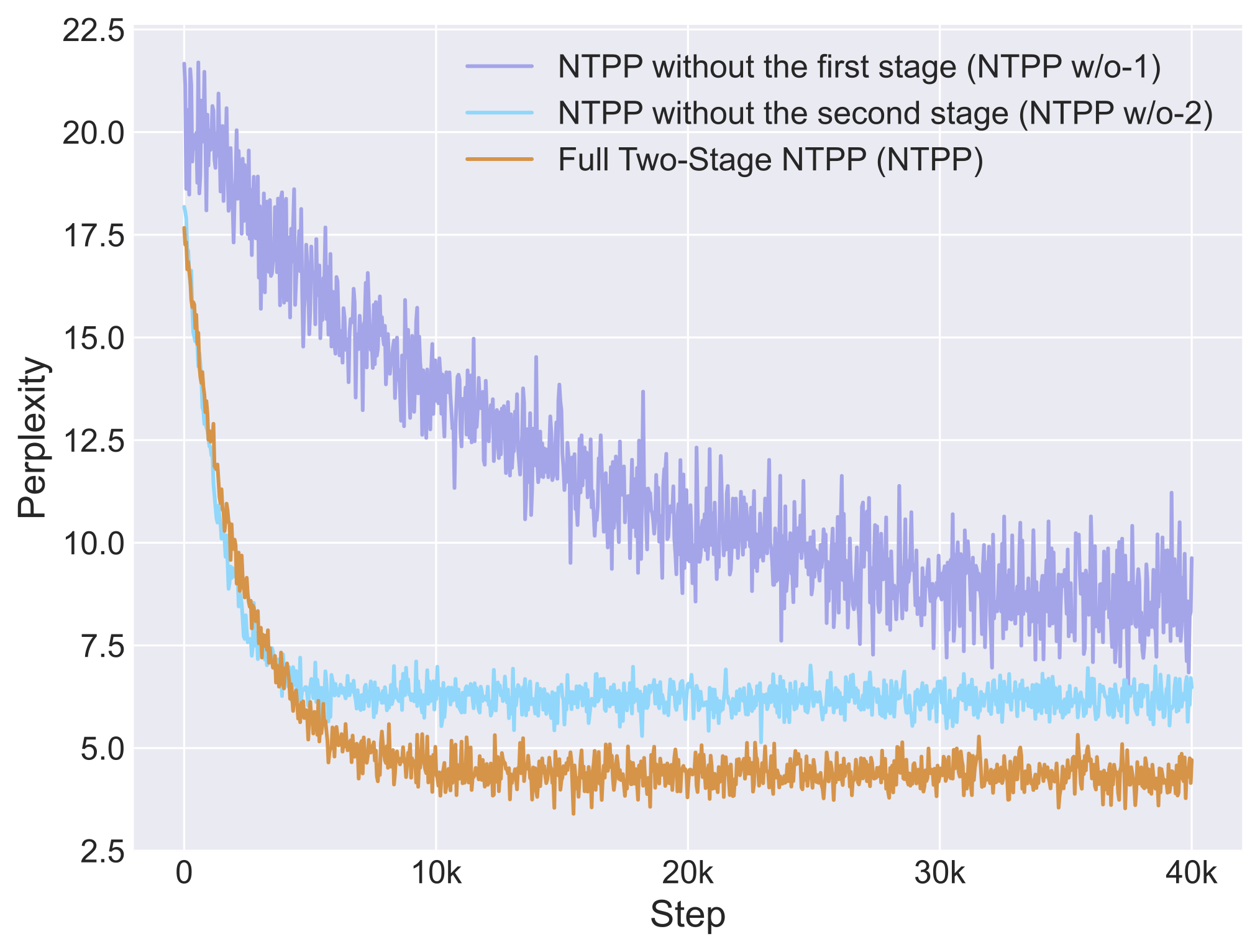
Figure 9: Ablation study comparing the performance of different training configurations: Full Two-Stage NTPP, NTPP without first stage pre-training, and NTPP without second stage fine-tuning
The ablation results in Figure 9 aim to support a simple claim: the first-stage training is essential before the second-stage NTPP training. We acknowledge that this may cause some confusion, so we have further clarified this ablation study with a slightly modified figure [Figure 9](audio-3059.pages.dev/figure9). This updated figure includes three curves: Full Two-Stage NTPP (NTPP), NTPP without the first stage (NTPP w/o-1), and NTPP without the second stage (NTPP w/o-2). The results clearly demonstrate that skipping either stage leads to suboptimal performance, with the absence of first-stage pre-training being particularly detrimental. This validates our two-stage training strategy and highlights importance of proper model initialization through pre-training before proceeding with the NTPP fine-tuning phase.
Further explanations on positional encoding
The positional encoding formula we use is RoPE. However, NTPP must determine several key aspects: which set of tokens should share the same RoPE (e.g., all tokens at the same timestep t), how to distinguish between speaker channels (using channel embeddings), and how to differentiate depth tokens (through cyclic depth encoding). Equations 9, 10, and 12 correspond to these three embeddings. It's important to note that equations 8 and 9 follow the implementation details of Llama, specifically in how they are added to the queries and keys.